Let’s imagine the case when you need to load a large amount of rows into database through Entity Framework application. If you had tried that, you know this process is very-very slow.
1. Worst case for performance
|
|
foreach (var client in clients) { context.Clients.Add(client); context.SaveChanges(); } |
SaveChanges() will open connection, start transaction and make one INSERT, and so on for all records. Then commit that unique record and closes connection.
2. Less worse case
|
|
foreach (var client in clients) { context.Clients.Add(client); } context.SaveChanges(); |
This time SaveChanges() opens connections and starts transaction just once. Then it emits INSERT command for each record and commits all records simultaneously.
In both cases Entity Framework preserves entities in ChangeTracker with a state Unchanged after saving them in database. When you call SaveChanges() again, it iterates ChangeTracker collection to find what to save. The more items will be in ChangeTracker the more time is needed to process them all.
So you can try to restrict the number of entries in ChangeTracker or disable change tracking mechanism at all.
To restrict the number of entries in ChangeTracker you can do:
- recreate DbContext;
- remove entries from ChangeTracker by setting the state to Detached.
So you can save some records (a batch), then get rid of all unnecessary entries from ChangeTracker.
|
|
foreach (var entry in ctx.ChangeTracker.Entries()) { entry.State = EntityState.Detached; } |
DbContext.Configuration has two options that could improve the performance:
- ValidateOnSaveEnabled – when it’s false, EF does not validate entity against model;
- AutoDetectChangesEnabled – when it’s false, EF does not compare original and current states of entities and does not change the state of the entity automatically. In other words, you can change the entity, but EF won’t notice that.
I’ve made a test to estimate the performance for the following cases where I call SaveChanges() method:
- immediately after each record was added to context;
- after all records;
- after adding a batch of records;
- after adding a batch of records, then recreating a DbContext;
- after adding a batch of records, then removing entries from ChangeTracker collection;
- after all records where ValidateOnSaveEnabled and/or AutoDetectChangesEnabled options are turned off.
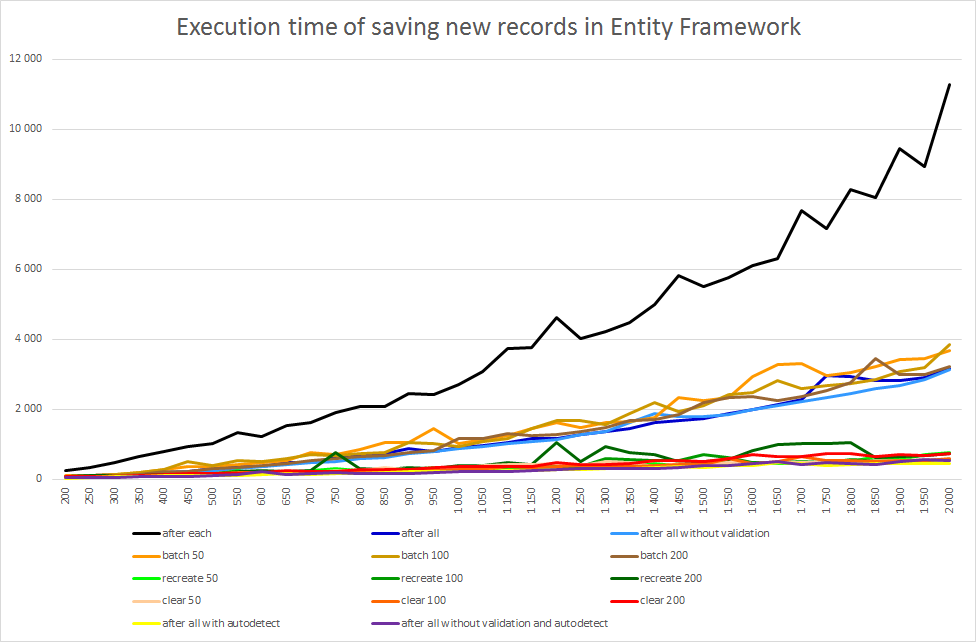
Here is the graphical representation of a series of tests using different number of records (from 200 to 2000) and different sizes of batches (50, 100 or 200).

There are 3 trends:
- highest – where SaveChanges() occurs after each record. Of course, committing every INSERT is much longer then committing a batch.
- medium – saving after all records or a batch were added.
- lowest – where ChangeTracker collection were not allowed to grow too much or ChangeTracker auto-detect feature was turned off.
On my opinion, there are two preferable ways to optimize the Entity Framework performance for massive write operations:
- call SaveChanges() after adding a relatively small batch of records and remove entries from ChangeTracker collection;
- turn off AutoDetectChangesEnabled option.
I would not recommend to recreate a DbContext cause you can have some additional code executed of context creation. Also recreation will clear EF cache for metadata and queries. These would lead to a negative impact on overall performance.
If you set AutoDetectChangesEnabled = false, don’t forget to switch back when you return to normal operations. Otherwise EF could overlook updates in entities.