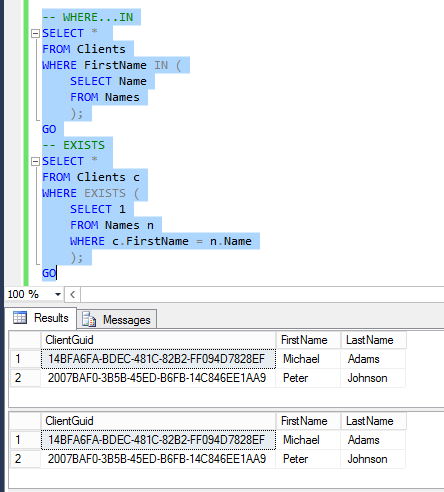
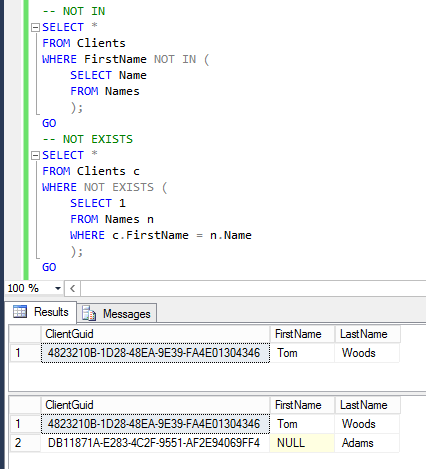
To use Help in SQL Server 2014 in offline mode you should perform the following steps:
1) install Documentation Components – at least you need the Help Viewer to see the content of help library
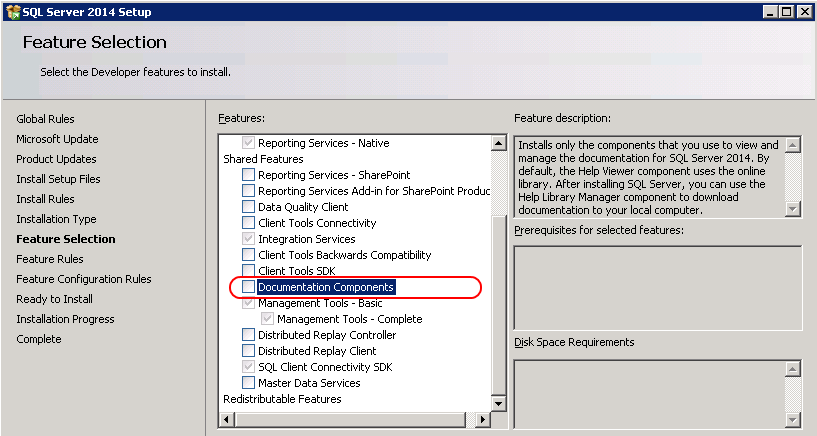
2) download the installer from Microsoft site Product Documentation for Microsoft SQL Server 2014 for firewall and proxy restricted environments
3) run the installer SQLServer2014Documentation_August2014_EN.exe
4) unzip files to a folder (I prefer to manually create a folder and unzip files there)
5) launch Help Settings
This can be made from Windows Start menu (Microsoft SQL Server 2014 -> Documentation & Community -> Manage Help Settings) or from SQL Server Management Studio (Help -> Manage Help Settings)
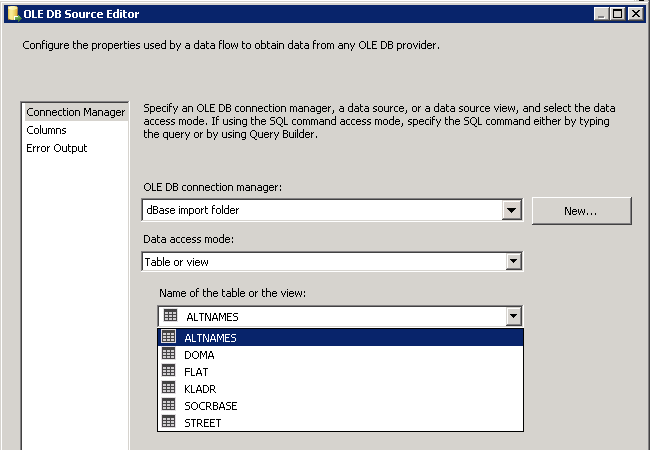
6) click Install content from disk in the Help Library Manager window
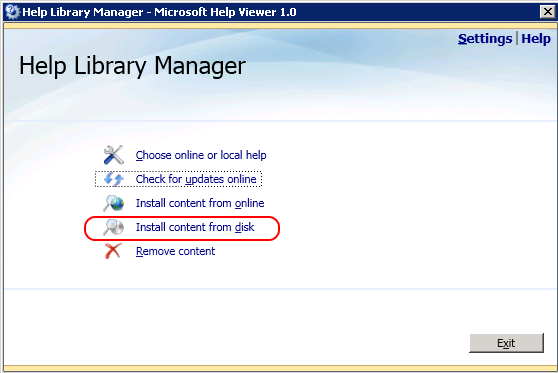
7) locate the folder to which you have unzipped the files at step 4 and select the file HelpContentSetup.msha, then press Open
8) press Next in the Help library Manager
9) click the links in Actions column to select the desired sections, then press Update
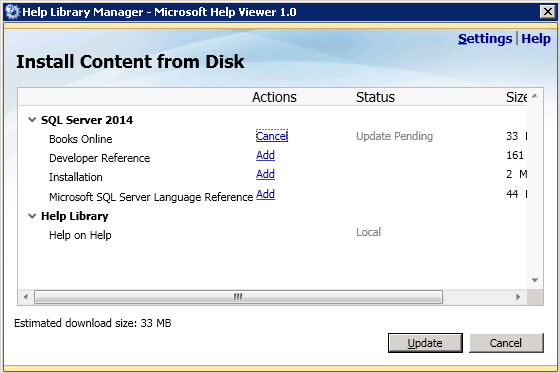
10) after you’ll see a message “Finished updating” press Finish button, then press Exit
11) now you can delete the folder with unzipped files
Tip: to check that you are really using the local help start Manage Help Settings again, click the first link Choose online or local help, and ensure the setting is correct.